 UI
UI
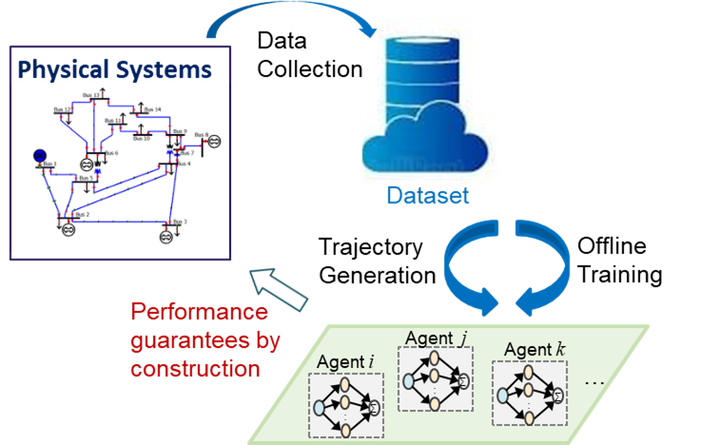
A key barrier to using reinforcement learning (RL) in many real-world applications is the requirement of a large number of system interactions to learn a good control policy. Off-policy and Offline RL methods have been proposed to reduce the number of interactions with the physical environment by learning control policies from historical data. However, their performances suffer from the lack of exploration and the distributional shifts in trajectories once controllers are updated. Moreover, most RL methods require that all states are directly observed, which is difficult to be attained in many settings.
To overcome these challenges, we propose a trajectory generation algorithm, which adaptively generates new trajectories as if the system is being operated and explored under the updated control policies. Motivated by the fundamental lemma for linear systems, assuming sufficient excitation, we generate trajectories from linear combinations of historical trajectories. For linear feedback control, we prove that the algorithm generates trajectories with the exact distribution as if they are sampled from the real system using the updated control policy. In particular, the algorithm extends to systems where the states are not directly observed. Experiments show that the proposed method significantly reduces the number of sampled data needed for RL algorithms.
Wenqi Cui
Assistant Professor
My research interests include control, machine learning and optimization for cyber-physical energy systems.